全模拟光电芯片用于高速视觉任务
清华大学的研究人员最近报告了他们在视觉芯片设计方面的发现(DOI:10.1038/s41586-023-06558-8)。
研究人员提出了一种名为全模拟芯片结合电子与光计算(ACCEL)的全模拟芯片,该芯片结合了电子与光计算,以完成高速视觉任务。ACCEL将衍射光学模拟计算(OAC)和电子模拟计算(EAC)融合到一个芯片中,以实现每秒4.6 Peta-操作的计算速度,这比最先进的计算处理器高一个数量级以上。该芯片利用衍射光学计算进行特征提取,并直接使用光诱导的光电流进行进一步的计算,无需模拟到数字转换器,并实现每帧72 ns的低计算延迟。ACCEL对于各种任务展示了具有竞争力的分类准确性,并在低光照条件下显示出超强的系统鲁棒性。ACCEL的潜在应用包括可穿戴设备,自动驾驶和工业检查。ACCEL芯片的系统能效为每瓦特每秒74.8 Peta-操作,并实现每秒4.6 Peta-操作的计算速度,分别比最先进的计算芯片高三个和一个数量级。该芯片结合了光子和电子计算的优点,实现了高速和低功耗的视觉任务。它能直接处理非相干或部分相干光,减少功耗,提高处理速度,无需额外的传感器或光源。ACCEL展示了高速识别能力,对于视频判定任务的100个测试样本,实验分类精度达到85%。ACCEL的分类准确度分别为85.5%、82.0%和92.6%,用于Fashion-MNIST、3类ImageNet分类、和时间延迟视频识别任务。它在低光照条件下表现优秀,比数字神经网络(NNs)在光强降低时保持特性更好。该芯片的部分可重配置性使得即使使用固定的衍射光学计算模块也能在不同任务上具有可比拟的性能,展示了它的灵活性和适应性。ACCEL在可穿戴设备、机器人、自动驾驶、工业检查和医疗诊断中有广泛的实际应用。
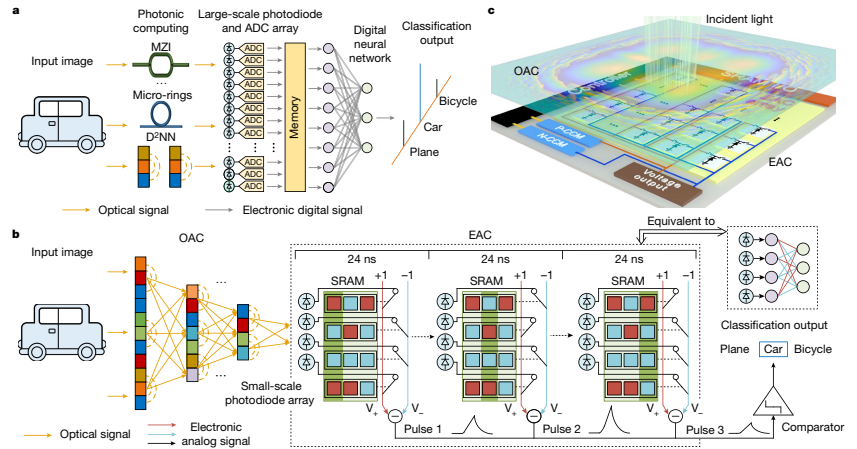
在视觉任务中存在需要将光信号转换为数字信号进行后处理的挑战。这个转换过程涉及到大规模光电二极管和耗电的模拟到数字转换器(ADCs)。实现精确的光非线性和内存也会增加系统级的延迟和功耗。为了应对这些挑战,研究人员提出了一种光电混合架构,减少了大规模ADCs的需求,使得在不降低任务性能的情况下,实现高速和低功耗的视觉任务。这种架构采用全模拟方法,通过照亮目标用一致光或非一致光将信息编入光场中。该架构的关键组建是ACCEL(全模拟卷积事件驱动学习)模块,该模块位于常见成像系统的像平面,用于直接图像处理和分类。ACCEL模块由两部分组成:光学模拟计算(OAC)模块和电子模拟计算(EAC)模块。OAC模块是一个多层衍射光学计算模块,它以光速运行。它使用训练好的相位掩模通过点积操作和光衍射对光场中编码的数据进行处理,从而从高分辨率图像中提取特征。这允许在无需光电转换的情况下对数据进行降维。从OAC模块中提取的特征被编码入光场并连接到EAC模块。EAC模块由光电二极管阵列组成,该阵列根据光电效应将光信号转换为模拟电子信号。每个光电二极管根据存储在静态随机存取存储器(SRAM)中的权重连入正线或负线。生成的光电流在两条线上求和,并由模拟减法器计算出作为输出的差分电压。EAC模块等效于一个非线性激活函数和二值权全连接神经网络(NN)。 EAC模块的输出可以直接用作分类的预测标签或作为另一个数字NN的输入。 在全模拟计算中,输出脉冲的数量(Ntt)对应于二进制NN中的输出节点的数量,可以根据所需的分类类别设置。携带单个EAC核心的ACCEL模块,通过输出对应于EAC模块中二进制NN的Ntt输出节点的多个脉冲来顺序工作。 所有这些功能都可以以全模拟方式集成到单个芯片上,使其适合各种应用并与现有的数字NN兼容以完成更复杂的任务。
他们介绍了一个光编码器,并描述了如何使用基于瑞利-索末菲尔衍射理论的数字光束传播对相位掩模中的权重进行训练。他们使用三层数字神经网络来以只有2%的采样从MNIST数据集重构图像,展示了光编码器的数据压缩能力。此外,他们展示,当光编码器的输出用于与数字神经网络进行分类,可以通过显著减少采样实现同样的精度。这意味着,模拟到数字转换器(ADCs)的数量可以减少98%,而不损害精度。然而,他们注意到,更复杂的任务或连接更简单的网络可能会降低压缩率,并需要更高维度的特征空间。
他们还介绍了他们使用的电子模拟计算器(EAC)的架构,该计算器由32x32的像素电路组成。这些电路形成了一个大小为1,024xNoutput的计算矩阵,其中Noutput代表输出节点的数量。在他们制作的芯片中,Noutput的最大值为16。每个像素电路包括一个产生用于模拟计算的光电流(Iph,i)的光电二极管。它还包括三个开关和一块SRAM(静态随机存取存储器)宏,用于存储二进制网络权重(wij)。光电二极管的阴极根据权重的值,连接到每个输出节点的正计算线(V+)或负计算线(V-)。在执行推断前,片上控制器将训练过的权重写入SRAM宏。在运行过程中,累积光电流及其相应的权重会放电计算线。这导致了电压降低,该电压用于EAC中的进一步处理。
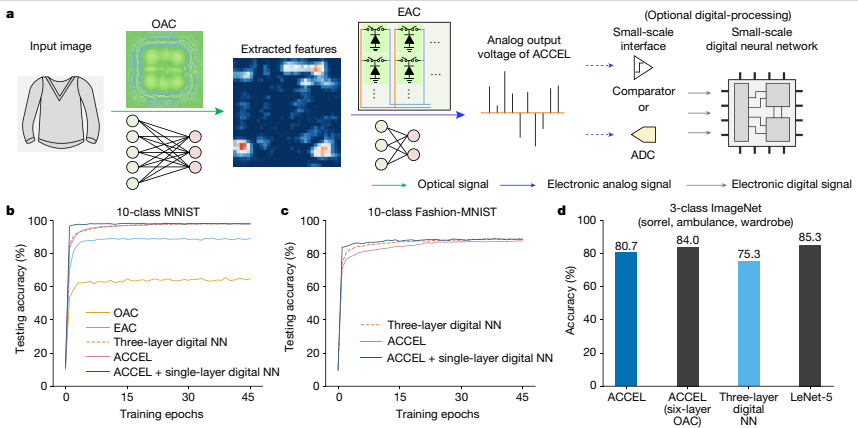
他们报告了ACCEL在各种任务中实现的分类精度。数值模拟显示,对于不同的数据集,包括10-class MNIST、10-class Fashion-MNIST和3-class ImageNet,ACCEL都有良好的分类精度。ACCEL在分类精度上超过了仅使用EAC和仅使用OAC的方法,显示其在视觉任务中的优越性能。还可以以低成本将小型数字神经网络(NN)连接到ACCEL,以完成更复杂的任务或适用于延时应用。他们还报告了ACCEL在低光条件下的低计算延迟和鲁棒性。在使用衍射光学计算作为特征提取的光编码器后,直接在集成的模拟计算芯片中使用光诱导光电流进行进一步的计算,消除了对模拟到数字转换器的需求。ACCEL实现了每帧72 ns的低计算延迟,并在低光条件下显示出具有竞争力的精度。这展示了ACCEL在可穿戴设备、自动驾驶和工业检查等应用中的潜力。他们展示了ACCEL在能效和计算速度方面的实验性能。ACCEL实现的系统计算速度为4.55 × 10^3 TOPS(tera-operations per second)和能效为7.48 × 10^4 TOPS W−1(每瓦特每秒浮点运算次数),比现有的最先进方法高数个数量级。对于3类ImageNet分类,ACCEL的实验系统能量消耗平均为4.4 nJ,而实验系统的能效计算出来为7.48 × 10^4 TOPS W−1。这些结果强调了ACCEL的能效和可扩展性,使其适于各种智能视觉任务。